UID888239性别保密经验 EP铁粒 粒回帖0主题精华在线时间 小时注册时间2023-2-2最后登录1970-1-1
| 本帖最后由 daijunhao 于 2025-9-6 15:38 编辑
# 前言
最近我有一大把空闲时间(也不知道要干什么)
直到我看到了mcpedl下载Curseforge直连的资源需要等待好几秒后才公布下载链接
所以我就开始分析起mcpedl了
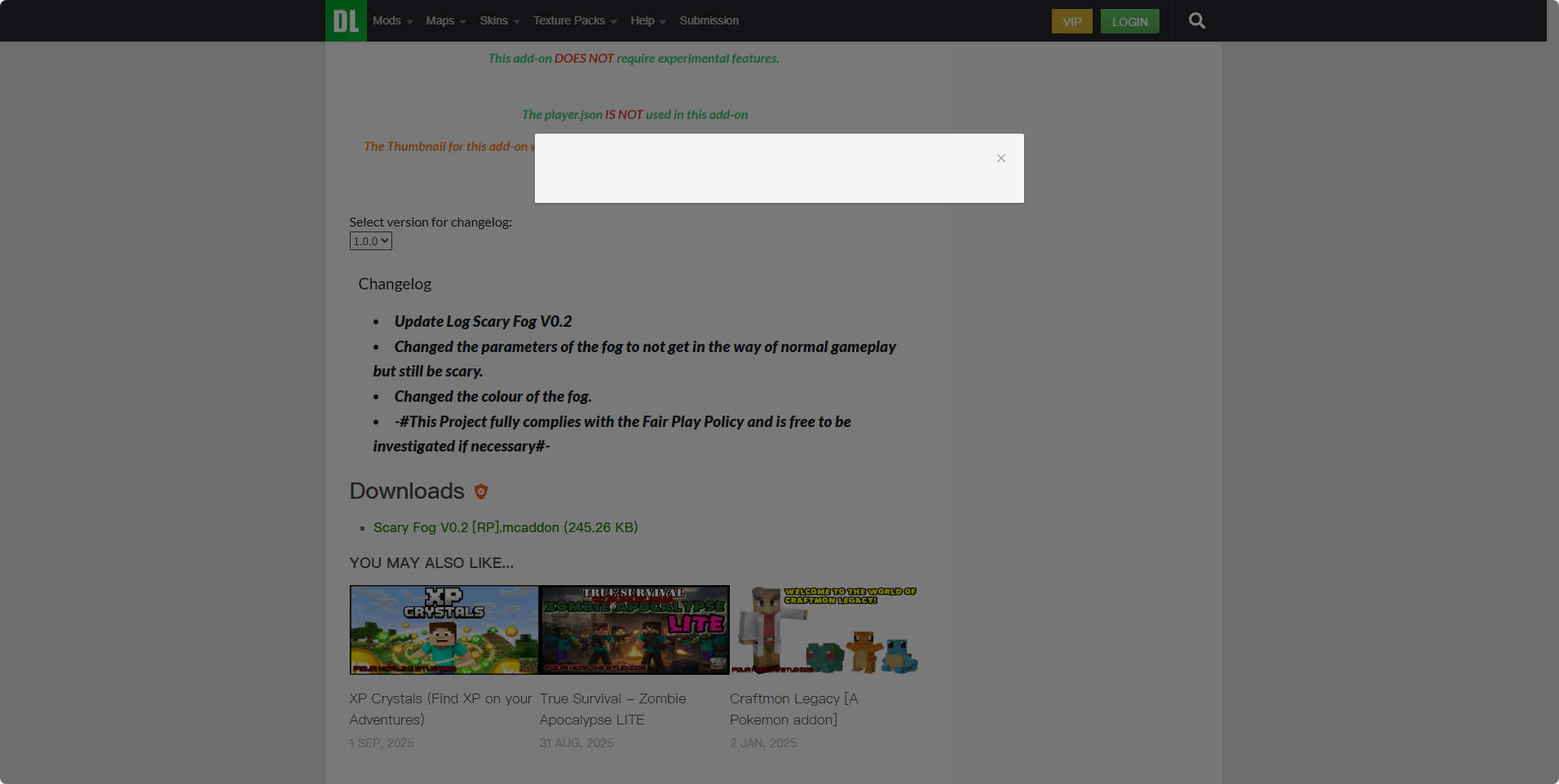
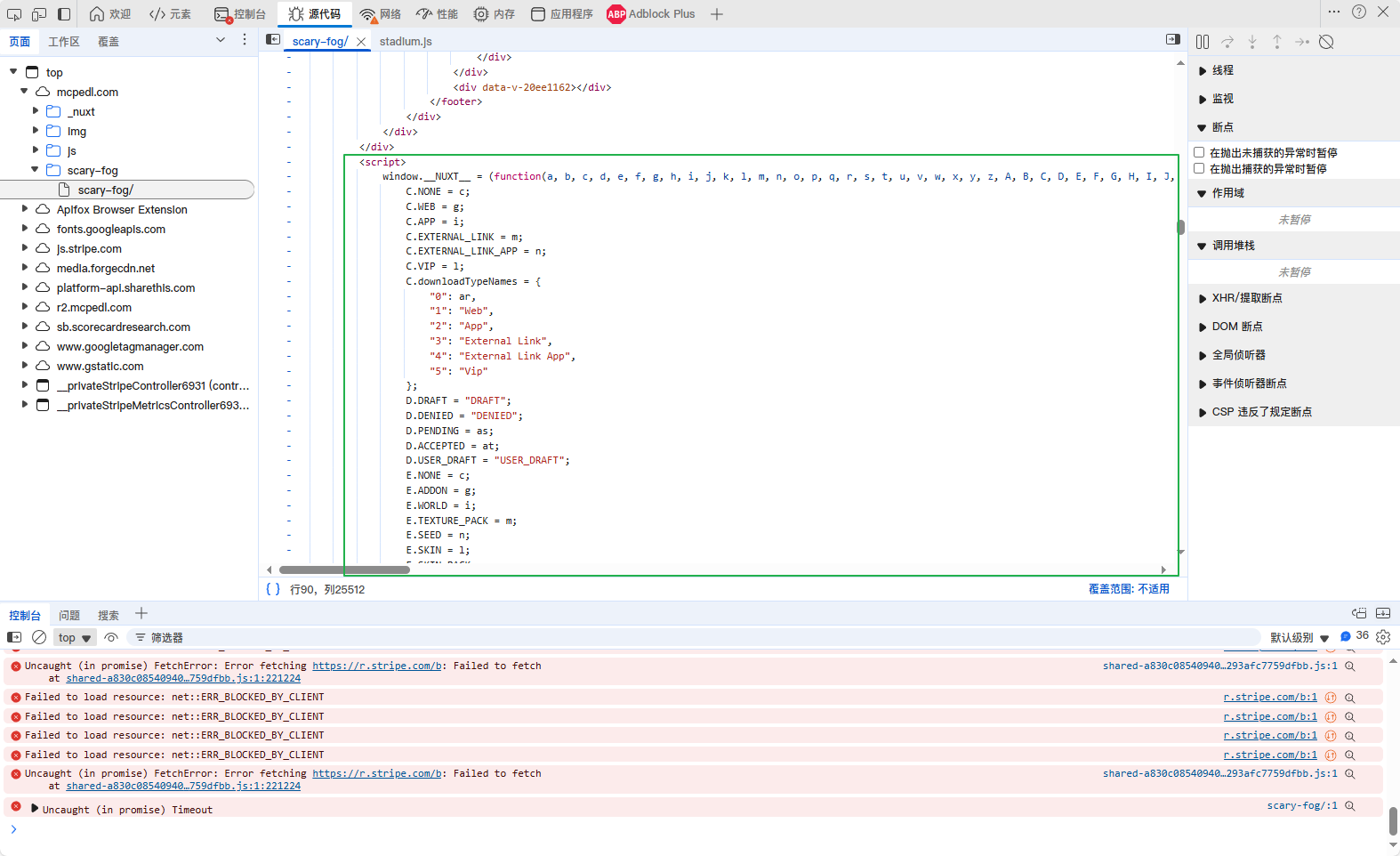
下面图片为我这边点击下载链接的情况(无法加载验证码,需特殊环境)
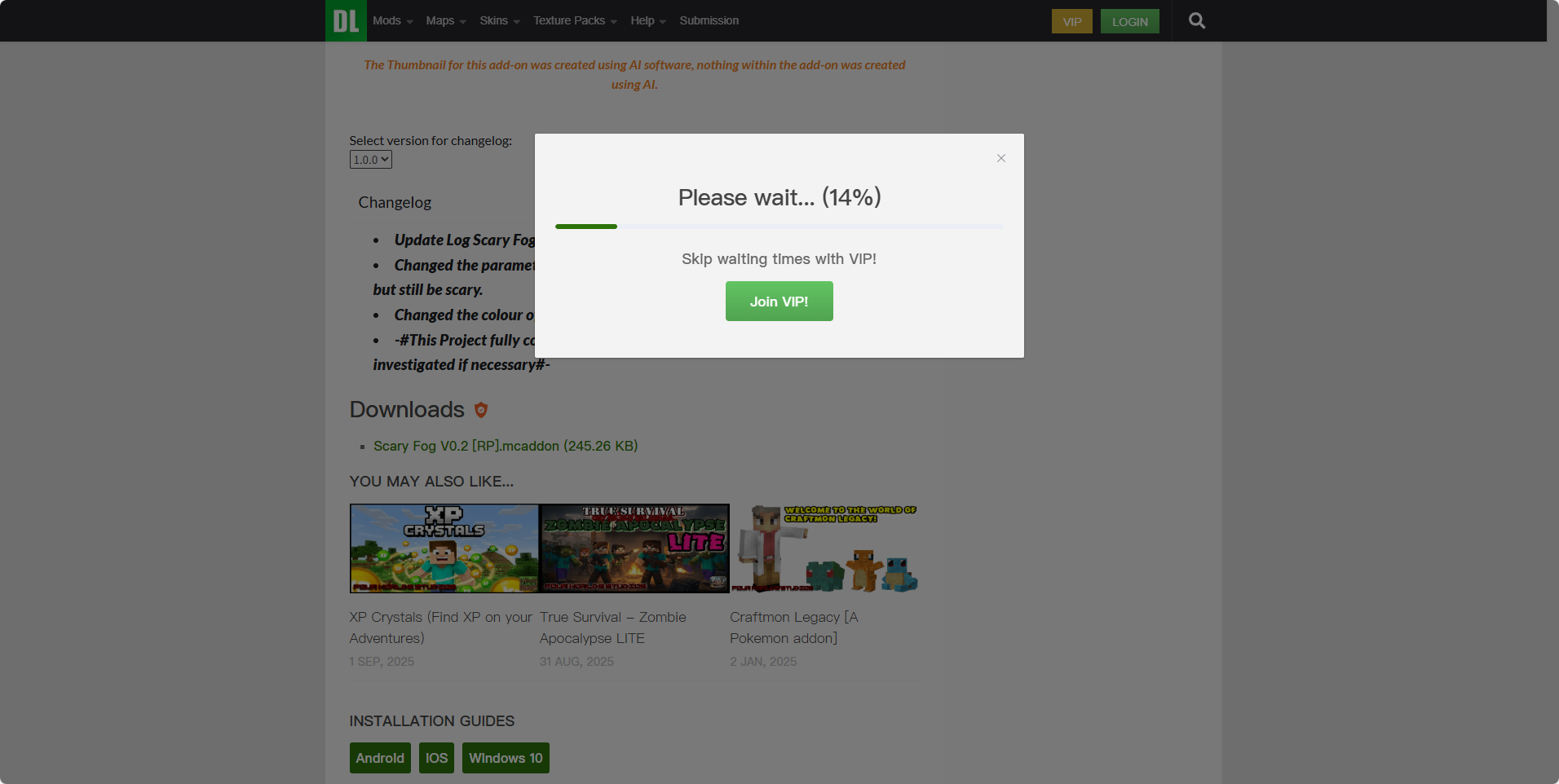
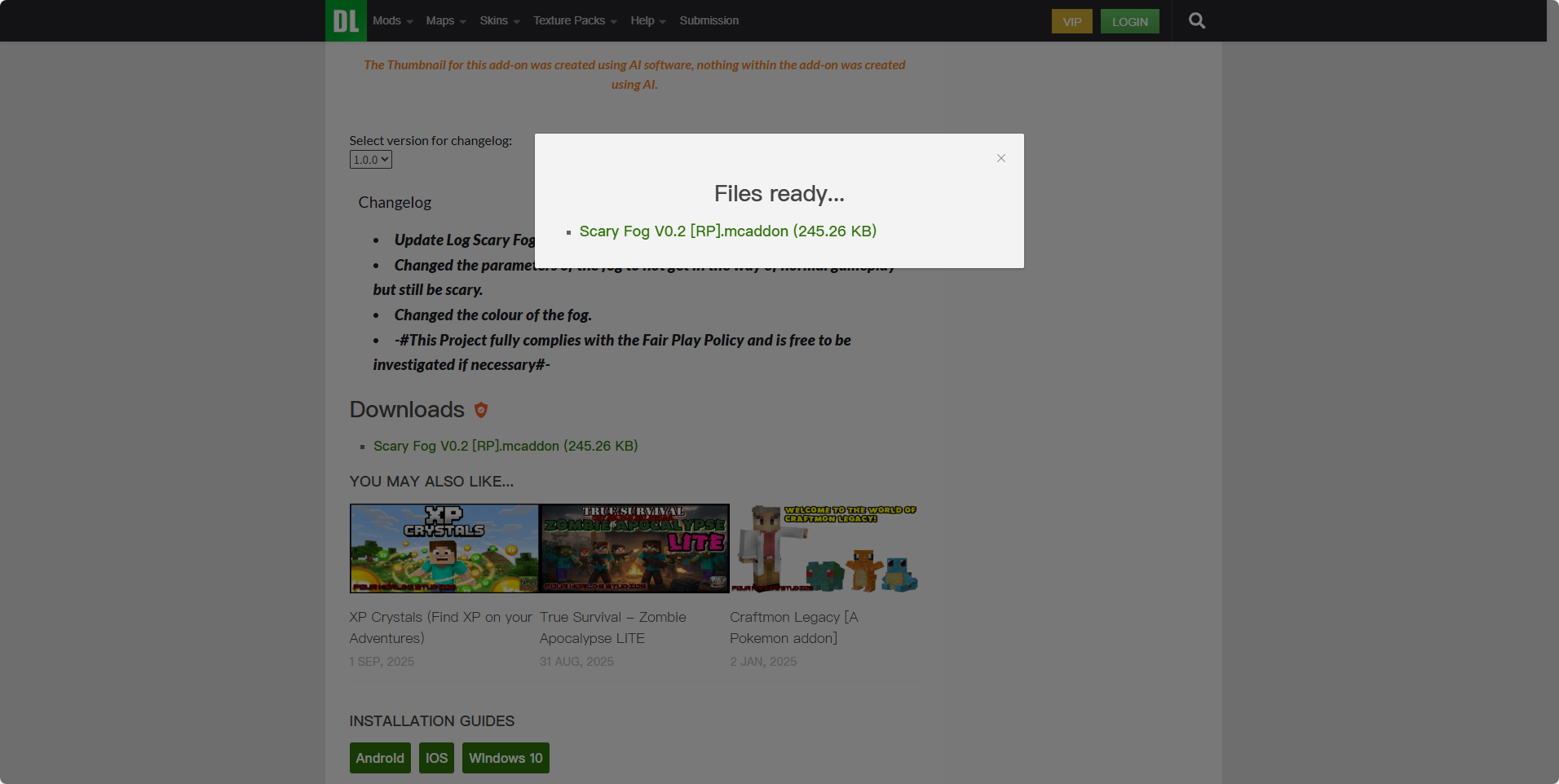
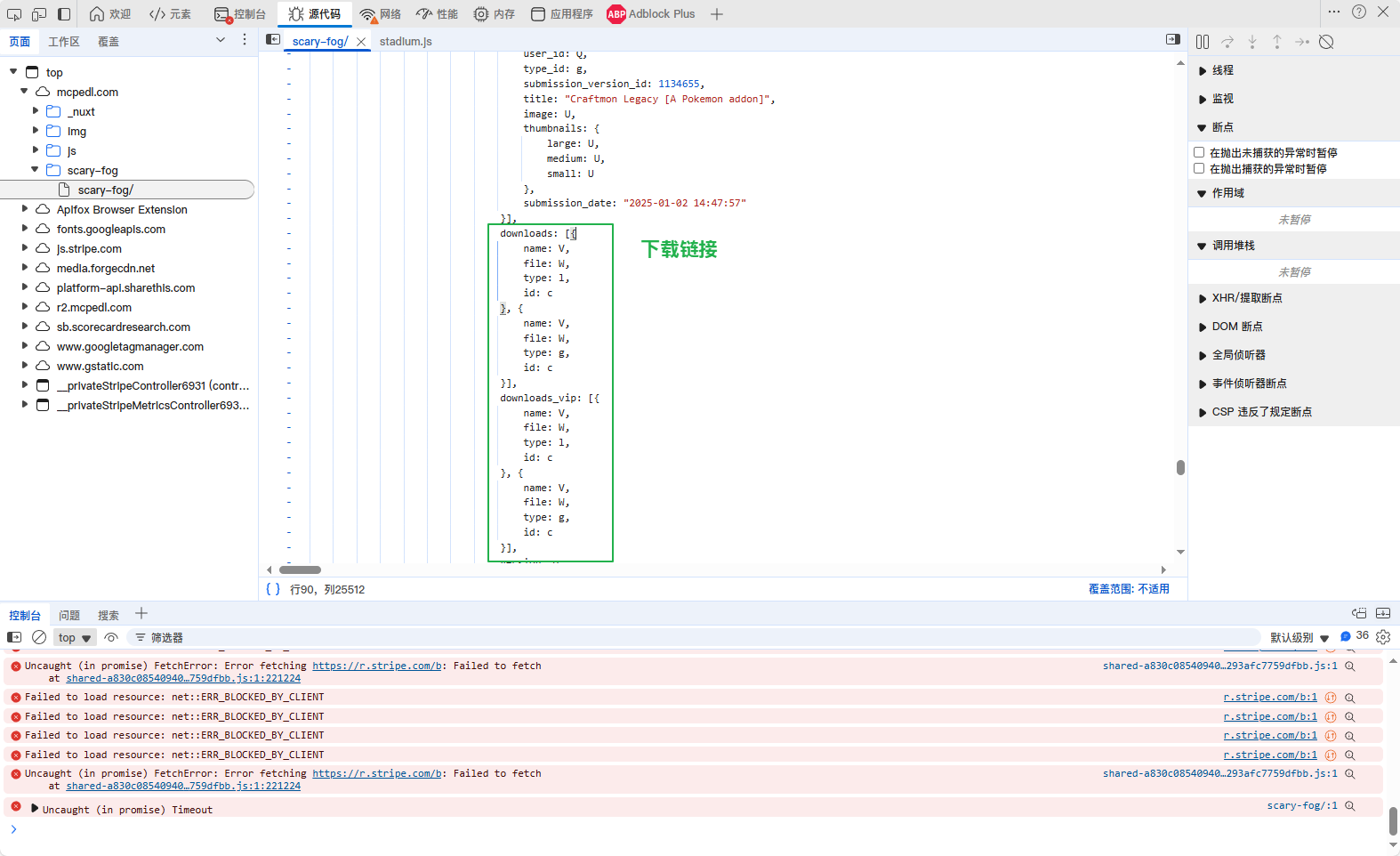
下面图片为获取到的下载链接
# 原理分析
首先Python直接requests是不可以的(有cloudflare的5秒盾)
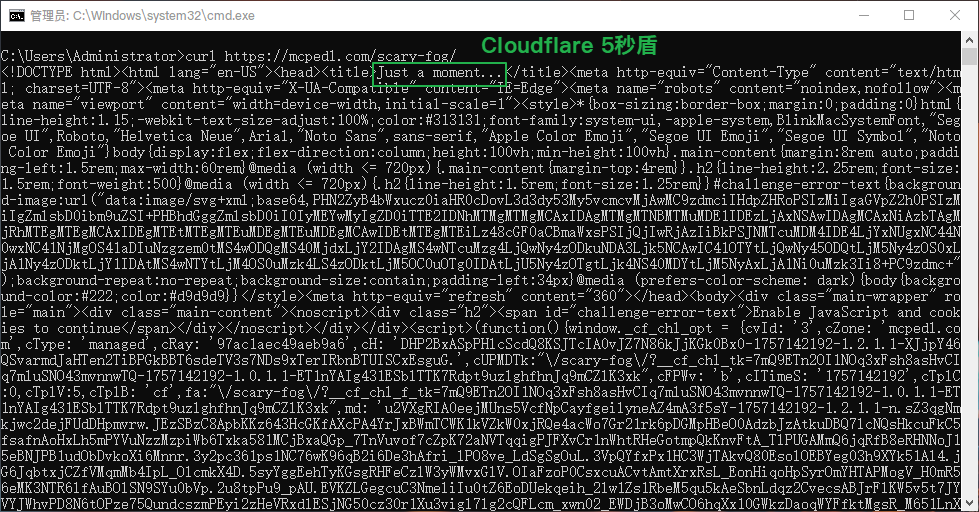
但是我找到解决方案:使用curl_cffi模拟浏览器指纹即可轻易解决这个盾

很好,目前已经解决掉了Cloudflare的5秒盾验证,已经解决了很多问题
示例代码:
- from curl_cffi import requests
- # 模拟 Chrome 120 的指纹(包括 TLS、HTTP2、ALPN、Header 顺序等)
- r = requests.get(
- "填入Url",
- impersonate="chrome120", # 关键!模拟真实浏览器指纹
- headers={
- "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36"
- }
- )
- soup = BeautifulSoup(r.text, 'lxml')
其实下载链接就在script里面
但是下载链接不好提取(建议是直接执行js脚本获取返回内容再从json中提取下载链接)
使用py2js去执行脚本示例:
- soup = BeautifulSoup(r.text, 'lxml')
- nuxt_script_tag = soup.find('script', string=lambda text: text and 'window.__NUXT__' in text)
- if not nuxt_script_tag:
- raise HTTPException(status_code=400, detail="错误: 未能在文件中找到包含'__NUXT__'数据的 script 标签。")
- script_content = nuxt_script_tag.string
- iife_start_index = script_content.find('(function')
- if iife_start_index == -1:
- raise HTTPException(status_code=400, detail="错误: 未能找到 IIFE 函数的起始位置。")
- iife_code = script_content[iife_start_index:]
- # 使用 js2py 执行 JS 代码
- js_result = js2py.eval_js(iife_code)
- nuxt_data = js_result.to_dict()
所以我选择使用nodejs + subprocess去解决这个问题
示例:
soup = BeautifulSoup(r.text, 'lxml')
nuxt_script_tag = soup.find('script', string=lambda text: text and 'window.__NUXT__' in text)
if not nuxt_script_tag:
raise HTTPException(status_code=404, detail="错误: 未能在页面中找到包含'__NUXT__'数据的 script 标签。")
script_content = nuxt_script_tag.string
iife_start_index = script_content.find('(function')
if iife_start_index == -1:
raise HTTPException(status_code=400, detail="错误: 未能找到 IIFE 函数的起始位置。")
iife_code = script_content[iife_start_index:]
node_script_for_stdin = f"console.log(JSON.stringify({iife_code[:-1]}))"
try:
# 运行 Node.js 进程,并通过 stdin 管道传入我们的脚本
# 这可以完美避免所有命令行特殊字符的转义问题
result = subprocess.run(
['node'], # 只启动 node 进程
input=node_script_for_stdin, # 将脚本作为标准输入传递
capture_output=True,
text=True,
check=True,
encoding='utf-8'
)
nuxt_data = json.loads(result.stdout)
except FileNotFoundError:
raise HTTPException(status_code=500, detail="错误: 'node' 命令未找到。请确保你已经在服务器上正确安装了 Node.js 并且其路径已添加到系统 PATH 环境变量中。")
except subprocess.CalledProcessError as e:
# e.stderr 会包含 Node.js 报出的真实错误,这对于调试非常有用
raise HTTPException(status_code=500, detail=f"Node.js 脚本执行失败: {e.stderr}")
except json.JSONDecodeError:
raise HTTPException(status_code=500, detail="错误: 无法解析来自 Node.js 的输出为 JSON。")
当nuxt_data正常返回是一个json数组的时候,那么这个时候就已经获取到下载链接了(json位置:["state"]["slug"]["model"]["downloads"])
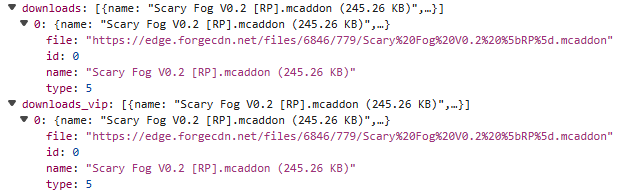
同时["state"]["slug"]["model"]这个位置的json会有更新日期、模组的详细信息(html格式)、更新日志等
## 资源解析
我开了一个mcpedl的资源解析站:https://mcpedl.theconsole.top
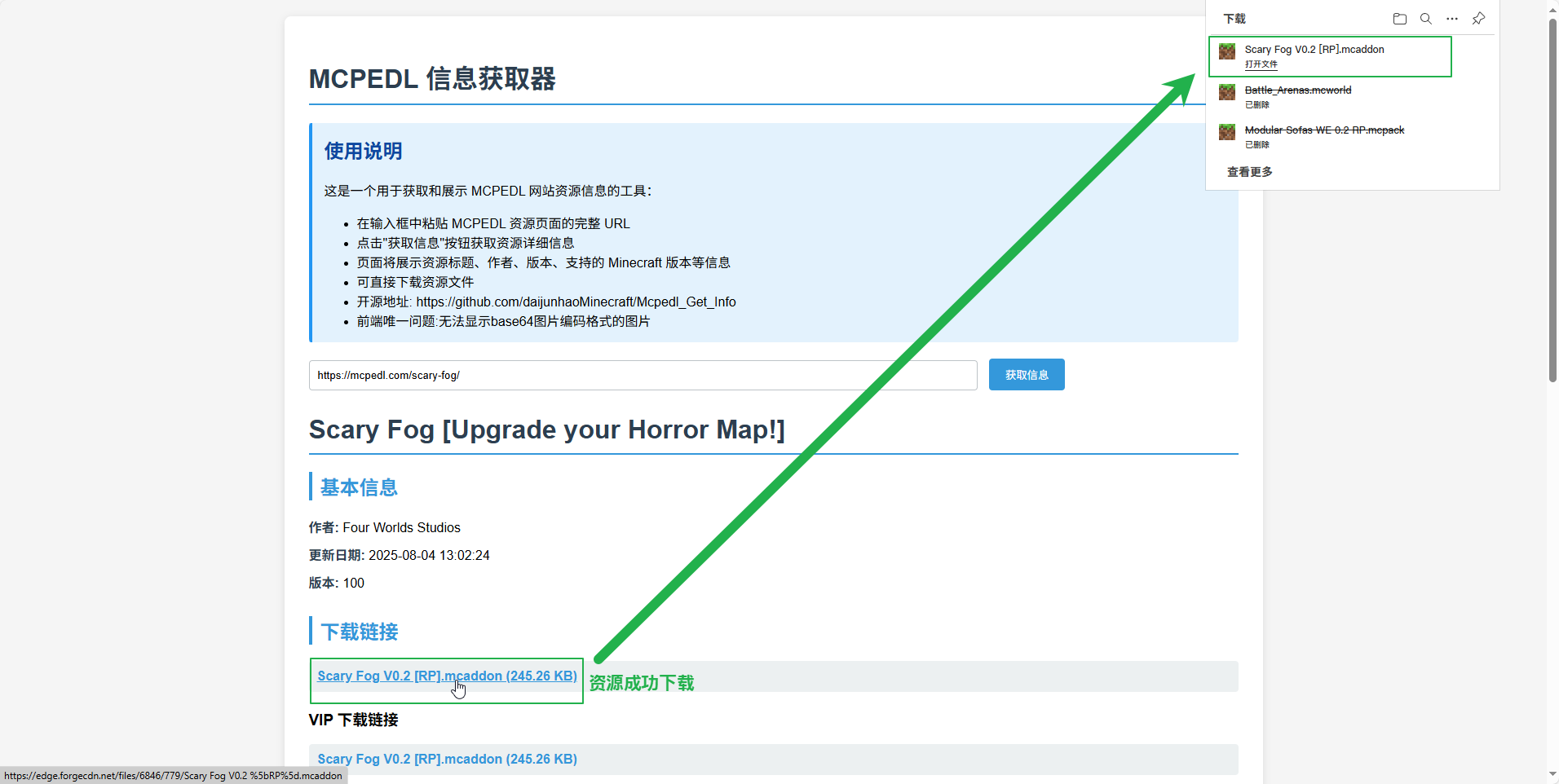
## 总结
无技术含量的爬虫(纯获取网页源代码+script函数执行就可以获取到详细信息)
开源地址:https://github.com/daijunhaoMinecraft/Mcpedl_Get_Info
|
|



 发表于 2025-9-6 15:25:11
发表于 2025-9-6 15:25:11 提升卡
提升卡 观察者
观察者